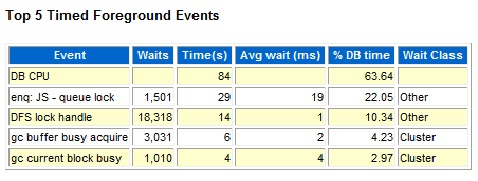
ARCH wait on SENDREQ -- Is Network related Wait event at Primary database side when a standby database is configured. ARCH wait on SENDREQ monitors the amount of time spent by all archiver processes to write the received redo to disk as well as open and close the remote archived redo logs

There are three things one can do if you have high wait time against this wait event.
1) Optimize the Network -
Overall, the goal for all Data Guard configurations is to ship redo data to the remote disaster recovery site fast enough to meet recovery time and recovery point objectives. If there is insufficient bandwidth available to handle the required volume however, no amount of tuning can achieve this goal. In order to figure out how much bandwidth is needed, the volume of data that is generated by the production database will need to be determined. Ideally, this can be found by measuring an existing production database or a database which has been set up in a test environment.
SDU (SESSION DATA UNIT)
Before sending data across the network, Oracle Net buffers data into the Session Data Unit (SDU). When large amounts of data are being transmitted or when the message size is consistent, increasing the size of the SDU buffer can improve performance and network utilization. You can configure SDU size within an Oracle Net connect descriptor or globally within the sqlnet.ora.
For Data Guard broker configurations configure the DEFAULT_SDU_SIZE parameter in the sqlnet.ora file:
DEFAULT_SDU_SIZE=32767
For non Data Guard broker configurations that use a connect descriptor, you can override the current settings in the primary database sqlnet.ora file. If you are setting the SDU in a connect descriptor you must use a static SID. Using a dynamic service registration will use the default SDU size defined by DEFAULT_SDU_SIZE. This example uses a connect descriptor with the SDU parameter in the description.
sales.us.acme.com=
(DESCRIPTION=
(SDU=32767)
(ADDRESS=(PROTOCOL=tcp)
(HOST=sales-server)
(PORT=1521))
(CONNECT_DATA=
(SID=sales.us.acme.com))
)
On the standby database, set SDU in the SID_LIST of the listener.ora file:
SID_LIST_listener_name=
(SID_LIST=
(SID_DESC=
(SDU=32767)
(GLOBAL_DBNAME=sales.us.acme.com)
(SID_NAME=sales)
(ORACLE_HOME=/usr/oracle)))
2) Multiple archive processes can transmit a redo log in parallel to the standby database, reducing the time for the redo transmission to the secondary. The MAX_CONNECTIONS attribute of the LOG_ARCHIVE_DEST_n control the number of these processes. This can be very beneficial during batch loads.
3)A system's network queues sizes can also be adjusted to optimize performance. You can regulate the size of the queue between the kernel network subsystems and the driver for network interface card. Any queue should be sized so that losses do not occur due to local buffer overflows. Therefore, careful tuning is required to ensure that the sizes of the queues are optimal for your network connection, particularly for high bandwidth networks.
These settings are especially important for TCP because losses on local queues cause TCP to fall into congestion control, which limits the TCP sending rates.
For Linux there are two queues to consider, the interface transmit queue and the network receive queue. The transmit queue size is configured with the network interface option txqueuelen. The network receive queue size is configured with the kernel parameter netdev_max_backlog
----- Find below more events related to Standby Database on Primary and Standby sides.----
WAIT EVENTS ON THE PRIMARY
On the primary database there are two categories of wait events which are either related to the ARC process or the LGWR process. The descriptions of these events are below.
1. ARCH PROCESS WAIT EVENTS
ARCH wait on ATTACH monitors the amount of time spent by all archiver processes to spawn an RFS connection.
ARCH wait on SENDREQ monitors the amount of time spent by all archiver processes to write the received redo to disk as well as open and close the remote archived redo logs.
ARCH wait on DETACH monitors the amount of time spent by all archiver processes to delete an
RFS connection.
2. LGWR SYNC WAIT EVENTS
LGWR wait on ATTACH monitors the amount of time spent by all log writer processes to spawn an RFS connection.
LGWR wait on SENDREQ monitors the amount of time spent by all log writer processes to write the received redo to disk as well as open and close the remote archived redo logs.
LGWR wait on DETACH monitors the amount of time spent by all log writer processes to delete an RFS connection.
3. LGWR ASYNC WAIT EVENTS
LNS wait on ATTACH monitors the amount of time spent by all network servers to spawn an RFS connection.
LNS wait on SENDREQ monitors the amount of time spent by all network servers to write the received redo to disk as well as open and close the remote archived redo logs.
LNS wait on DETACH monitors the amount of time spent by all network servers to delete an RFS connection.
LGWR wait on full LNS buffer monitors the amount of time spent by the log writer (LGWR) process waiting for the network server (LNS) to free up ASYNC buffer space. If buffer space has not been freed in a reasonable amount of time, availability of the primary database is not compromised by allowing the archiver process (ARCn) to transmit the redo log data. This wait event is not relevant for destinations configured with the LGWR SYNC=PARALLEL attributes.
WAIT EVENTS ON THE SECONDARY
RFS Write is the elapsed time for the write to standby redo log or archive log to occur as well as non I/O work such as redo block checksum validation.
RFS Random I/O is the elapsed time for the write to a standby redo log to occur.
RFS Sequential I/O is the elapsed time for the write to an archive log to occur.

There are three things one can do if you have high wait time against this wait event.
1) Optimize the Network -
Overall, the goal for all Data Guard configurations is to ship redo data to the remote disaster recovery site fast enough to meet recovery time and recovery point objectives. If there is insufficient bandwidth available to handle the required volume however, no amount of tuning can achieve this goal. In order to figure out how much bandwidth is needed, the volume of data that is generated by the production database will need to be determined. Ideally, this can be found by measuring an existing production database or a database which has been set up in a test environment.
SDU (SESSION DATA UNIT)
Before sending data across the network, Oracle Net buffers data into the Session Data Unit (SDU). When large amounts of data are being transmitted or when the message size is consistent, increasing the size of the SDU buffer can improve performance and network utilization. You can configure SDU size within an Oracle Net connect descriptor or globally within the sqlnet.ora.
For Data Guard broker configurations configure the DEFAULT_SDU_SIZE parameter in the sqlnet.ora file:
DEFAULT_SDU_SIZE=32767
For non Data Guard broker configurations that use a connect descriptor, you can override the current settings in the primary database sqlnet.ora file. If you are setting the SDU in a connect descriptor you must use a static SID. Using a dynamic service registration will use the default SDU size defined by DEFAULT_SDU_SIZE. This example uses a connect descriptor with the SDU parameter in the description.
sales.us.acme.com=
(DESCRIPTION=
(SDU=32767)
(ADDRESS=(PROTOCOL=tcp)
(HOST=sales-server)
(PORT=1521))
(CONNECT_DATA=
(SID=sales.us.acme.com))
)
On the standby database, set SDU in the SID_LIST of the listener.ora file:
SID_LIST_listener_name=
(SID_LIST=
(SID_DESC=
(SDU=32767)
(GLOBAL_DBNAME=sales.us.acme.com)
(SID_NAME=sales)
(ORACLE_HOME=/usr/oracle)))
2) Multiple archive processes can transmit a redo log in parallel to the standby database, reducing the time for the redo transmission to the secondary. The MAX_CONNECTIONS attribute of the LOG_ARCHIVE_DEST_n control the number of these processes. This can be very beneficial during batch loads.
3)A system's network queues sizes can also be adjusted to optimize performance. You can regulate the size of the queue between the kernel network subsystems and the driver for network interface card. Any queue should be sized so that losses do not occur due to local buffer overflows. Therefore, careful tuning is required to ensure that the sizes of the queues are optimal for your network connection, particularly for high bandwidth networks.
These settings are especially important for TCP because losses on local queues cause TCP to fall into congestion control, which limits the TCP sending rates.
For Linux there are two queues to consider, the interface transmit queue and the network receive queue. The transmit queue size is configured with the network interface option txqueuelen. The network receive queue size is configured with the kernel parameter netdev_max_backlog
----- Find below more events related to Standby Database on Primary and Standby sides.----
WAIT EVENTS ON THE PRIMARY
On the primary database there are two categories of wait events which are either related to the ARC process or the LGWR process. The descriptions of these events are below.
1. ARCH PROCESS WAIT EVENTS
ARCH wait on ATTACH monitors the amount of time spent by all archiver processes to spawn an RFS connection.
ARCH wait on SENDREQ monitors the amount of time spent by all archiver processes to write the received redo to disk as well as open and close the remote archived redo logs.
ARCH wait on DETACH monitors the amount of time spent by all archiver processes to delete an
RFS connection.
2. LGWR SYNC WAIT EVENTS
LGWR wait on ATTACH monitors the amount of time spent by all log writer processes to spawn an RFS connection.
LGWR wait on SENDREQ monitors the amount of time spent by all log writer processes to write the received redo to disk as well as open and close the remote archived redo logs.
LGWR wait on DETACH monitors the amount of time spent by all log writer processes to delete an RFS connection.
3. LGWR ASYNC WAIT EVENTS
LNS wait on ATTACH monitors the amount of time spent by all network servers to spawn an RFS connection.
LNS wait on SENDREQ monitors the amount of time spent by all network servers to write the received redo to disk as well as open and close the remote archived redo logs.
LNS wait on DETACH monitors the amount of time spent by all network servers to delete an RFS connection.
LGWR wait on full LNS buffer monitors the amount of time spent by the log writer (LGWR) process waiting for the network server (LNS) to free up ASYNC buffer space. If buffer space has not been freed in a reasonable amount of time, availability of the primary database is not compromised by allowing the archiver process (ARCn) to transmit the redo log data. This wait event is not relevant for destinations configured with the LGWR SYNC=PARALLEL attributes.
WAIT EVENTS ON THE SECONDARY
RFS Write is the elapsed time for the write to standby redo log or archive log to occur as well as non I/O work such as redo block checksum validation.
RFS Random I/O is the elapsed time for the write to a standby redo log to occur.
RFS Sequential I/O is the elapsed time for the write to an archive log to occur.