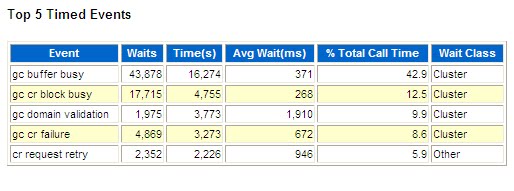
gc buffer busy
The gc current block busy and gc cr block busy wait events indicate that the local instance that is making the request did not immediately receive a current or consistent read block. The term "busy" in these events' names indicates that the sending of the block was delayed on a remote instance. For example, a block cannot be shipped immediately if Oracle Database has not yet written the redo for the block's changes to a log file.
In comparison to "block busy" wait events, a gc buffer busy event indicates that Oracle Database cannot immediately grant access to data that is stored in the local buffer cache. This is because a global operation on the buffer is pending and the operation has not yet completed. In other words, the buffer is busy and all other processes that are attempting to access the local buffer must wait to complete.
The existence of gc buffer busy events also means that there is block contention that is resulting in multiple requests for access to the local block. Oracle Database must queue these requests.
Usually, either interconnect or load issues or SQL execution against a large shared working set can be found to be the root cause.
gc buffer busy‟ waits can happen for many reasons. Few of them are: CPU starvation issues, Swapping issues, interconnect issues etc. For example, if the process that opened the request for a block did not get enough CPU, then it might not drain the network buffers to copy the buffer to buffer cache. Other sessions accessing that buffer will wait on „gc buffer busy‟ waits. Or If there is a network issue and the Global cache messages are slower, then it might induce higher gc buffer busy waits too. Statistics „gc lost packets‟ is a good indicator for network issues, but not necessarily a complete indicator.
Solution
If this wait event was found on the top 5 wait events then one has to immediately look for "Segments by Global Cache Buffer Busy" section of the AWR to check buffers of which objects are contributing to the wait event. Then look for Sql Statements which are being fired from multiple instances and see if one can reduce the contention either by ensuring that applications which perform transactions on these objects very frequently should be pointed to a single node or look for other issues like cache values of sequences on these objects or CPU , network, interconnect , large loads etc.
No comments:
Post a Comment